マルチホップのパターンと積算
マルチホップパターンで最短経路を指定する
1つのホップのパターンを何回も繰り返すことは便利なときもありますが、パターンマッチングの真のパワーは、異なる特徴を持つホップを複数指定できる、マルチホップパターンにあります。例えば、商品のおすすめに「この製品を購入した方はこちらの製品も購入されています」という文句がよく使われますが、これは次のような2ホップパターンで表現することができます。
FROM This_Product:p -(<Bought:b1)- Customer:c -(Bought>:b2)- Product:p2
WHERE p2 != pご覧のように、2ホップパターンは、2つの同一のエンドポイントのある1ホップパターンを単純に連結して結合したものです。次の例では、Y:yが連結するエンドポイントです。
2ホップのパターン
FROM X:x - (E1:e1) - Y:y - (E2>:e2) - Z:z同様に、3ホップのパターンは、3つの1ホップパターンを順番に連結して結合したもので、隣り合わせのホップ同士には共通のエンドポイントがあります。次の例では、Y:yとZ:zが連結するエンドポイントです。
3ホップのパターン
FROM X:x - (E2>:e2) - Y:y - (<E3:e3) - Z:z - (E4:e4) - U:u一般的に、1ホップパターンをN個結合して、Nホップパターンを作成することができます。データベースは、グラフのトポロジーを検索して、Nホップのパターンと一致するサブグラフを探します。
無名な中間頂点セット
マルチホップパターンにはエンドポイントを持つ頂点セットが2つと、中間頂点セットが1つ以上あります。中間頂点セットに条件を指定する必要がないクエリの場合、中間頂点セットを省くことができ、外側のエッジセットを "." で簡単に繋ぐことができます。例えば、上の2ホップパターンの場合、中間頂点Yの種類を指定しなくてもよければ、また、クエリのWHEREやACCUMなどの他の句でもその頂点を照会する必要がなければ、パターンは次のように省略できます。
FROM X:x - (E1.E2>) - Z:z|
このようにパスを省略した場合には、省略された部分のエッジのエイリアスや中間頂点のエイリアスは無効になります。 |
可変パターンでは最短経路のみ有効
パターンに米印によるエッジの反復が含まれている場合、GSQLのパターンマッチング機能は、パターンと一致する最短経路のみを選択します。このように制限しないと、コンピューターサイエンスの理論上、演算時間が無限または極端に長くなる(技術的な表現ではNP=非多項式時間を要する)可能性があります。反復の上限なしで米印が使われているときに、演算時間の長さを無視して一致するパスをすべて探そうとすると、グラフ内にループがある場合には、マッチは無限数になる可能性があります。例えループがなくても、また、上限が指定されていても、確認するパスの数はホップ数が増えるに従って指数関数的に増加します。
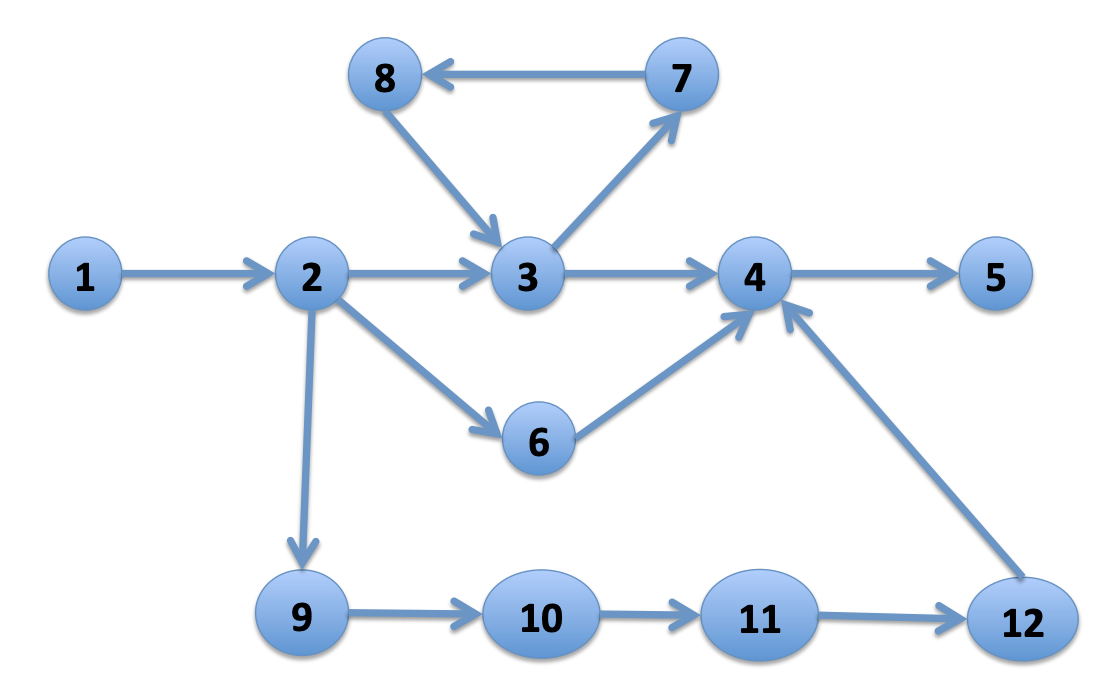
上の図3にあるパターン 1 - (_*) - 5 から次のことがわかります。
-
最短経路は2つ: 1-2-3-4-5 と 1-2-6-4-5
-
これらは4ホップなので、4回ホップしたら検索を止めることができます。そうすれば扱いやすい作業になります。
-
-
頂点を1回しか通らないパスをすべて探すと:
-
頂点を繰り返して通らないパスは3つ: 1-2-3-4-5 と 1-2-6-4-5 と 1-2-9-10-11-12-4-5
-
実際のマッチ数は少ないのですが、理論上、パスの数は膨大です。
-
-
エッジを1回しか通らないパスをすべて探すと:
-
エッジを繰り返して通らないパスは4つ: 1-2-3-4-5 と 1-2-6-4-5 と 1-2-9-10-11-12-4-5 と 1-2-3-7-8-3-4-5
-
実際のマッチ数は少ないのですが、考慮すべきパスの数はNPになります。
-
-
制限なしにすべてのパスを探すと:
-
3-7-8-3 のサイクルを無限回巡回できるので、マッチ数は無限大になります。
-
パターンマッチングの追加情報
|
パターンマッチングの初期のバージョン (TigerGraph v2.4 ~ v2.6) では、WHERE、ACCUM、POST-ACCUMの句にさまざまな制限がありました。TigerGraph 3.0では、そのほとんどが解除されています。 |
あるパターン内の各頂点セットと、クリーネスター付きエッジを除いた各エッジセットには、エイリアス変数を関連付けることができます。クエリが実行されてマッチが見つかると、各エイリアスとグラフ内で一致した頂点やエッジが関連(結び)付けられます。
SELECT句
SELECT句は、SELECT文で出力する頂点セットを指定します。マルチホップパターンの場合、パターン内の任意の頂点エイリアスを選択することができます。次の例では、同じパターンに対して、4通りの選択が可能なことを表しています。
#開始するエンドポイント xの選択
SELECT x
FROM X:x-(E2>:e2)-Y:y-(<E3:e3)-Z:z-(E4:e4)-U:u;
#yの選択
SELECT y
FROM X:x-(E2>:e2)-Y:y-(<E3:e3)-Z:z-(E4:e4)-U:u;
#zの選択
SELECT z
FROM X:x-(E2>:e2)-Y:y-(<E3:e3)-Z:z-(E4:e4)-U:u;
#最終エンドポイントuの選択
SELECT u
FROM X:x-(E2>:e2)-Y:y-(<E3:e3)-Z:z-(E4:e4)-U:u;FROM句
マルチホップパターンの場合、中間頂点を照会する必要がない場合、 "." を使ってエッジパターンを結び付けて、簡潔な指示にできます。例えば、次の例では、yとzを取り除いて、ピリオドの記号を使って E2> と <E3 と E4 を結合しています。なお、E2>.<E3.E4 のようなマルチホップのシーケンスにはエイリアスが使えないことに注意してください。
#開始するエンドポイント xの選択
SELECT x
FROM X:x-(E2>:e2)-Y:y-(<E3:e3)-Z:z-(E4:e4)-U:u;
#yとzにアクセスする必要がない場合には、次のように記述できます
SELECT u
FROM X:x-(E2>.<E3.E4)-U:u;WHERE句
TigerGraph v3.0より、各述部(単純な true/false 条件))はパス内の任意のエイリアスを照会できるようになりました。データベースクエリに一般なことですが、条件が複雑なクエリの場合、述部の規定が単純でよりローカルな場所を指している、簡単なクエリと同じようなパフォーマンスは期待できません。例えば、次のパターンとクエリを比較してみましょう
FROM X1:x1-(E1:e1)-X2:x2-(E2:e2)-X3:x3-(E3:e3)-X4:x4# (x1, e1, x2) は最初のホップの内容
# (x2, e2, x3) は2番目のホップの内容
# (x3, e3, x4) は最後のホップの内容
# below x1.age > x2.age はローカル述部
# x2.@cnt != x4.@cnt はクロスホップ述部
# (x1.salary + x3.salary) < x4.salary はクロスホップ述部
SELECT x
FROM X1:x1-(E1:e1)-X2:x2-(E2:e2)-X3:x3-(E3:e3)-X4:x4
WHERE x1.age>x2.age AND x2.@cnt!=x4.@cnt AND (x1.salary+x3.salary)<x4.salary正規表現の言語として捉えたパスのパターン
GSQLのパターンマッチングの構文には、グラフ内のパスを指定するのに必要な基本的な正規表現言語が含まれています。正規表現に必要な3つの基本要件を見て見ましょう。
-
空のセット -→ 長さがゼロのパス(マッチなし)
-
連結 -→ NホップのパターンとMホップのパターンを別々に作成して、組み合わせて (N+M) ホップパターンを作ることができます。
-
交互指定(二者択一) -→ 頂点セットにもエッジセットにも交互指定が使えます。例えば
FROM (Source1 | Source2) -(Edge1> | <Edge 2)- (Target1 | Target2)注記: 上の例は次の例とは意味が異なります。FROM (Source1 -(Edge1>)- Target 1) | (Source2 -(<Edge2)- Target 2)後者は、SELECTクエリのブロックを2つ記述して、その結果の和集合 (UNION) を求めることによって得られます。
パターンマッチ作業について
パターンマッチングの目的は、入力したパターンと一致するグラフエンティティのセットを探し出すことです。 その結果が得られると、GSQLは次にそのデータを基に、高度な計算を効率よく行います。単純にマッチ数を計算することから、高度のアルゴリズムや分析処理まで、さまざまな計算が可能です。 このセクションでは、現在のパターンマッチング構文にある積算機能と初期のバージョンのものとを比較します。アキュムレーターそのものを一部始終説明するものではありません。 詳しくはアキュムレーターのチュートリアル と、GSQL 言語レファレンスセクションの ACCUM と POST-ACCUM句の解説をご覧ください。
ACCUM句
|
TigerGraph 3.0では、パターンマッチング (SYNTAX v2) に関する、WHERE、ACCUM、POST-ACCUM句の制限が取り除かれています。 |
従来のGSQL構文のように、ACCUM句は、FROMとWHERE句が指定するパターンと条件が一致するグラフ内の頂点セット毎、エッジセット毎に1回 ずつ(並列に)実行されます。FROM-WHEREは仮想の表を生成すると考えてもよいでしょう。このマッチングの表(マッチテーブル)の列は、FROM句にあるパターンからとったエイリアス変数であり、行は、パターンと一致する可能性のある頂点のエイリアスのセットとエッジのエイリアスのセット(パスなど)で、セット毎に並んでいます。
単純な1ホップのパターンは(構文のバージョンがv1の場合もv2の場合も)、次のようになります。
FROM Person:A -(IS_LOCATED_IN:B)- City:Cその結果、A、B、Cの3列があるマッチテーブルが生成されます。各行はタプル(A,B,C) で、 has_lived_in (に住んでいた)エッジB が Person (人)の頂点A から City (都市)の頂点Cを結び付けています。ここで、このマッチテーブルは、パターンのエイリアスとグラフの頂点とエッジの間に結合(バインド)を提供すると言います。マルチホップのパターンの場合には、単に1ホップのパターンより多くの列があります。
|
ACCUM節はすべてのマッチにおいて反復実行されます。パターン内のすべての頂点にエイリアスが指定されていない場合は、相違なるマッチの数は、マッチ数よりも少ないことがあります。 |
次の例を見てみましょう。
FROM Person:A -(KNOWS.KNOWS)- Person.C
WHERE C.email = "Andy@www.com"
ACCUM C.@patternCount += 1この節は、Andy@www.com. の友達の友達を求めています。Andyには、Wendy を知っている3人の知人(Larry、Moe、Curly)がいると仮定すると、アキュムレーター C.@patternCount がC = Wendyに対して3回加算されます。これは、SQLのクエリ SELECT C, COUNT(*) ... GROUP BY C に似ています。 KNOWS.KNOWS の中にある頂点にはエイリアスがないので、Larry、Moe、Curlyを識別する情報は取得できません。
POST-ACCUM句
|
TigerGraph 3.0 のパターンマッチング (V2) より、複数のPOST-ACCUM句を使うことができるようになりました。 |
ACCUM句の最後には、リクエストしたすべての積算の演算子 (+=) が一括処理され、その結果更新された値が表示されます。その後にPOST-ACCUM句を使って、パターンマッチングの結果に2度目の、異なる計算をすることができます。
ACCUM句はFROM句で指定しているパターンと一致する各フルパスに対して実行されます。しかし、POST-ACCUM句は、ある頂点セット(例えばマッチングテーブル内のある頂点列)内の各頂点に対して実行されます。POST-ACCUM句の命令文は、ACCUM句で計算されたアキュムレータの集約結果にアクセスできます。V3.0で導入された要件ですが、2つ以上の頂点エイリアスに対して、1頂点毎の更新を実行したい場合、頂点エイリアス毎に別々のPOST-ACCUM句を使う必要があります。 複数のPOST-ACCUM節は並行処理されます。句の作成順と処理の順番は関係ありません。(各結合(バインド)において、句内の命令文が順番に実行されます。)
例えば、次に2つのPOST-ACCUM句があります。最初の句はsを反復しながら処理していき、各sにおいて s.@cnt2 += s.@cnt1.を実行します。2つ目のPOST-ACCUMはtを反復しながら処理していきます。
USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
SumAccum<int> @cnt1;
SumAccum<int> @cnt2;
R = SELECT s
FROM Person:s-(LIKES>) -:msg - (HAS_CREATOR>)-Person:t
WHERE s.firstName == "Viktor" AND s.lastName == "Akhiezer"
AND t.lastName LIKE "S%" AND year(msg.creationDate) == 2012
ACCUM s.@cnt1 +=1 //execute this per match of the FROM pattern.
POST-ACCUM s.@cnt2 += s.@cnt1 //execute once per s.
POST-ACCUM t.@cnt2 +=1;//execute once per t
PRINT R [R.firstName, R.lastName, R.@cnt1, R.@cnt2];
}その結果は次のとおりです。
Using graph 'ldbc_snb'
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [
{"R": [{
"v_id": "28587302323577",
"attributes": {
"R.firstName": "Viktor",
"R.@cnt1": 3,
"R.lastName": "Akhiezer",
"R.@cnt2": 3
},
"v_type": "Person"
}]},
]
}しかし、次の指示は、1つのPOST-ACCUM句内の2つのエイリアス(sとt)が対象となっているので、無効です。
POST-ACCUM t.@cnt1 += 1,
s.@cnt1 += 1また、エイリアスは、1回の指示につき1つしか使用できません。次の例は無効です。
POST-ACCUM t.@cnt1 += s.@cnt + 1マルチホップパターンの一致例
例1.「TennisPlayer」という名前のTagClassの3つ目のスーパークラスを求める。
USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2 {
TagClass1 =
SELECT t
FROM TagClass:s-(IS_SUBCLASS_OF>.IS_SUBCLASS_OF>.IS_SUBCLASS_OF>)-TagClass:t
WHERE s.name == "TennisPlayer";
PRINT TagClass1;
}上記のGSQLスクリプトをexample1.qsglと名付けたファイルにコピーしてスクリプトファイルとすれば、Linuxから呼び出すことができます。
gsql example1.gsqlUsing graph 'ldbc_snb'
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [{"TagClass2": [{
"v_id": "239",
"attributes": {
"name": "Agent",
"id": 239,
"url": "http://dbpedia.org/ontology/Agent"
},
"v_type": "TagClass"
}]}]
}例2. 2011年1月に作成されたメッセージの内、直近の3つのメッセージがどの大陸で作成されたかを求める。
USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2{
SumAccum<String> @continentName;
accMsgContinent =
SELECT s
FROM (Comment|Post):s-(IS_LOCATED_IN>.IS_PART_OF>)-Continent:t
WHERE year(s.creationDate) == 2011 AND month(s.creationDate) == 1
ACCUM s.@continentName = t.name
ORDER BY s.creationDate DESC
LIMIT 3;
PRINT accMsgContinent;
}上記のGSQLスクリプトをexample2.qsglと名付けたファイルにコピーしてスクリプトファイルとすれば、Linuxから呼び出すことができます。
gsql example2.gsqlUsing graph 'ldbc_snb'
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [{"accMsgContinent": [
{
"v_id": "824640012997",
"attributes": {
"browserUsed": "Firefox",
"length": 7,
"locationIP": "27.112.21.246",
"@continentName": "Asia",
"id": 824640012997,
"creationDate": "2011-01-31 23:54:28",
"content": "no way!"
},
"v_type": "Comment"
},
{
"v_id": "824636727408",
"attributes": {
"browserUsed": "Firefox",
"length": 3,
"locationIP": "31.2.225.17",
"@continentName": "Europe",
"id": 824636727408,
"creationDate": "2011-01-31 23:57:46",
"content": "thx"
},
"v_type": "Comment"
},
{
"v_id": "824634837528",
"attributes": {
"imageFile": "",
"browserUsed": "Internet Explorer",
"length": 115,
"locationIP": "87.251.6.121",
"@continentName": "Asia",
"id": 824634837528,
"creationDate": "2011-01-31 23:58:03",
"lang": "tk",
"content": "About Adolf Hitler, iews. His writings and methods were often adapted to need and circumstance, although there were"
},
"v_type": "Post"
}
]}]
}例3. Viktor Akhiezerが2012年に最も好きだった作者の内、姓がSの文字で始まる人を求める。また、Viktorがその作者の投稿やコメントに「いいね!」を付加した回数を求める。
USE GRAPH ldbc_snb
INTERPRET QUERY () SYNTAX v2{
SumAccum<int> @likesCnt;
FavoriteAuthors =
SELECT t
FROM Person:s-(LIKES>) -:msg - (HAS_CREATOR>)-Person:t
WHERE s.firstName == "Viktor" AND s.lastName == "Akhiezer"
AND t.lastName LIKE "S%" AND year(msg.creationDate) == 2012
ACCUM t.@likesCnt +=1;
PRINT FavoriteAuthors[FavoriteAuthors.firstName, FavoriteAuthors.lastName, FavoriteAuthors.@likesCnt];
}上記のGSQLスクリプトをexample3.qsglと名付けたファイルにコピーしてスクリプトファイルとすれば、Linuxから呼び出すことができます。
gsql example3.gsqlUsing graph 'ldbc_snb'
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [{"FavoriteAuthors": [
{
"v_id": "8796093025410",
"attributes": {
"FavoriteAuthors.firstName": "Priyanka",
"FavoriteAuthors.lastName": "Singh",
"FavoriteAuthors.@likesCnt": 1
},
"v_type": "Person"
},
{
"v_id": "2199023260091",
"attributes": {
"FavoriteAuthors.firstName": "Janne",
"FavoriteAuthors.lastName": "Seppala",
"FavoriteAuthors.@likesCnt": 1
},
"v_type": "Person"
},
{
"v_id": "15393162796846",
"attributes": {
"FavoriteAuthors.firstName": "Mario",
"FavoriteAuthors.lastName": "Santos",
"FavoriteAuthors.@likesCnt": 1
},
"v_type": "Person"
}
]}]
}ブロックロックを複数使ったクエリ
ここまで、複雑なマルチホップパターンでも、例えパターンが連結されているものであっても、単独のSELECTクエリにある単独のFROM句によって表現できることを説明しました。しかし、SELECTブロックを複数使ってクエリを作成した方が良い、またはその必要が生じる場合もあります。計算とマッチングを段階的に進める必要がある場合、クエリを読みやすくしたり、パフォーマンスを最適化したりする必要がある場合などに適しています。
理由とは関係なく、GSQLではすべてのバージョンで、複数のSELECTクエリのブロックを使って手順を表すクエリの作成をサポートしています。その上、各SELECT文より頂点セットが出力され、出力された頂点セットは、後続のSELECTブロックのFROM句で使うことができます。
例えば、あるクエリで実行されたSELECTブロックの出力がSet1、Set2、Set3 とすると、その後、同じクエリで次のFROM句が各々実行できます。
-
FROM Set1:x1 -(mh1)- :x2 -(mh2)- Set3:x3 -
FROM :x1 -(mh1)- :x2 -(mh2)- Set3:x3 -
FROM Set2:x1 -(mh1)- :x2 -(mh2)- Set2:x3
例1. Viktor Akhiezerがメッセージを最も好きだった作者の内、姓がSの文字で始まる人を求める。その結果の作者と同じ大学出身の人の数を求める。
USE GRAPH ldbc_snb
# 計算の結果得られた頂点セットFが2つ目のパターンの条件になっています
INTERPRET QUERY () SYNTAX v2 {
SumAccum<int> @@cnt;
F = SELECT t
FROM :s -(LIKES>:e1)- :msg -(HAS_CREATOR>)- :t
WHERE s.firstName == "Viktor" AND s.lastName == "Akhiezer" AND t.lastName LIKE "S%";
Alumni = SELECT p
FROM Person:p -(STUDY_AT>) -:u - (<STUDY_AT)- F:s
WHERE s != p
Per (p)
POST-ACCUM @@cnt+=1;
PRINT @@cnt;
}
#結果
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [{"@@cnt": 216}]
}例2. Viktor Akhiezerが好きだった投稿の作者A、同様に好きだったメッセージの作者Bを求める。その中から、AとBのグループのメンバーが就学していた大学の数を求める。
USE GRAPH ldbc_snb
#AとBは、3つ目のパターンの条件として使われています
INTERPRET QUERY () SYNTAX v2 {
SumAccum<int> @@cnt;
A = SELECT t
FROM :s -(LIKES>:e1)- Post:msg -(HAS_CREATOR>)- :t
WHERE s.firstName == "Viktor" AND s.lastName == "Akhiezer" ;
B = SELECT t
FROM :s -(LIKES>:e1)- Comment:msg -(HAS_CREATOR>)- :t
WHERE s.firstName == "Viktor" AND s.lastName == "Akhiezer" ;
Univ = SELECT u
FROM A:p -(STUDY_AT>) -:u - (<STUDY_AT)- B:s
WHERE s != p
Per (u)
POST-ACCUM @@cnt+=1;
PRINT @@cnt;
}
#結果
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [{"@@cnt": 4}]
}例3. Find Viktor Akhiezer’s liked posts' authors A. See how many pair of persons in A that one person likes a message authored by another person.Viktor Akhiezerがいいね!した投稿の作者Aを求める。その中から、互いに作成したメッセージにいいね!した人達のペアの数を求める。
USE GRAPH ldbc_snb
# 計算の結果得られた頂点セットAが2つ目のパターンで2度使われています
INTERPRET QUERY () SYNTAX v2 {
SumAccum<int> @@cnt;
A = SELECT t
FROM :s -(LIKES>:e1)- Post:msg -(HAS_CREATOR>)- :t
WHERE s.firstName == "Viktor" AND s.lastName == "Akhiezer" ;
A = SELECT p
FROM A:p -(LIKES>) -:msg - (HAS_CREATOR>) - A:p2
WHERE p2 != p
Per (p, p2)
ACCUM @@cnt +=1;
PRINT @@cnt;
}
#結果
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [{"@@cnt": 14833}]
}例4. 名前がTの文字で始まる人の内、自分で作成したメッセージを好きな人の数を求める。
USE GRAPH ldbc_snb
# 同じエイリアスが1つのパターンで2回使われています
INTERPRET QUERY () SYNTAX v2 {
SumAccum<int> @@cnt;
A = SELECT msg
FROM :s -(LIKES>:e1)- :msg -(HAS_CREATOR>)- :s
WHERE s.firstName LIKE "T%"
PER (msg)
ACCUM @@cnt +=1;
PRINT @@cnt;
}
#結果
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [{"@@cnt": 207}]
}
#さらに検証をするために、上のクエリの結果から1つメッセージを取り出してみました
#自分で書いたメッセージにいいね!する人がいるでしょうか
INTERPRET QUERY () SYNTAX v2 {
R = SELECT s
FROM :msg -(HAS_CREATOR>)- :s
WHERE msg.id == 1374390714042;
T = SELECT s
FROM R:s -(LIKES>)- :msg
WHERE msg.id == 1374390714042;
PRINT R;
PRINT T;
}
#結果
{
"error": false,
"message": "",
"version": {
"schema": 0,
"edition": "enterprise",
"api": "v2"
},
"results": [
{"R": [{
"v_id": "13194139533433",
"attributes": {
"birthday": "1985-11-26 00:00:00",
"firstName": "Taras",
"lastName": "Kofler",
"gender": "female",
"speaks": [
"uk",
"ro",
"en"
],
"browserUsed": "Internet Explorer",
"locationIP": "31.131.28.133",
"id": 13194139533433,
"creationDate": "2011-01-29 01:14:27",
"email": [
"Taras13194139533433@gmail.com",
"Taras13194139533433@yahoo.com"
]
},
"v_type": "Person"
}]},
{"T": [{
"v_id": "13194139533433",
"attributes": {
"birthday": "1985-11-26 00:00:00",
"firstName": "Taras",
"lastName": "Kofler",
"gender": "female",
"speaks": [
"uk",
"ro",
"en"
],
"browserUsed": "Internet Explorer",
"locationIP": "31.131.28.133",
"id": 13194139533433,
"creationDate": "2011-01-29 01:14:27",
"email": [
"Taras13194139533433@gmail.com",
"Taras13194139533433@yahoo.com"
]
},
"v_type": "Person"
}]}
]
}##